In this article, I’ll describe a traditional machine learning workflow and then compare it to an MLOps-driven approach to show why it's highly relevant in the current AI landscape.
The traditional machine learning workflow
Traditional machine learning workflows are isolated. They are either on the developer's machine or another single development environment. While these can be accessible, like Google Collab notebooks, they are not scalable, nor do they offer features like dataset versioning or automated deployments.
In these traditional workflows, data is gathered from various sources like databases, logs, and external datasets. It then needs to be manually reviewed and cleaned to remove duplicates, correct errors, and fill in missing values. Dataset separation for training, validation, and evaluation is done by hand. In addition, transformations such as normalization or feature extraction have to be done manually. Automation is non-existent in this traditional process, which is not easily reproducible. As a result, collaboration between your ML developers, ops team, and data scientists becomes incredibly challenging.
During the model training phase, the training process is usually run on local machines or single servers without any automation or optimization frameworks. Instead, the models are trained and tested by launching scripts. Cross-validation can ensure the model generalizes effectively, but this isn't automated. Meanwhile, the deployment process involves exporting the model to a file and moving it to a server manually or with some loading and serving scripts. Monitoring consists of periodically checking logs and dashboards to ensure the system runs as expected.
And old-school ML workflows face even more issues. These include challenges related to data scaling, tracking and repeating experiments, deployments, and keeping up with model performance. On top of all of that, traditional processes result in barriers between ML engineers, data scientists, and operations teams because they lack a common, integrated platform for model development and releases.
In summary, standard machine learning pipelines involve:
- Manual Integration: Most steps rely heavily on human intervention, which are prone to mistakes.
- Siloed Workflow: Data scientists, engineers, and IT operations work in silos with minimal collaboration and communication.
- Limited Reproducibility: Reproducing experiments and training models is difficult due to a lack of version control for data, code, and models.
- Ad-hoc Monitoring: Model performance and system health monitoring aren't systematic. This makes it challenging to detect and respond to issues quickly.
- Lack of Scalability: Scaling the process is difficult, as the infrastructure isn't designed for continuous and large-scale operations.
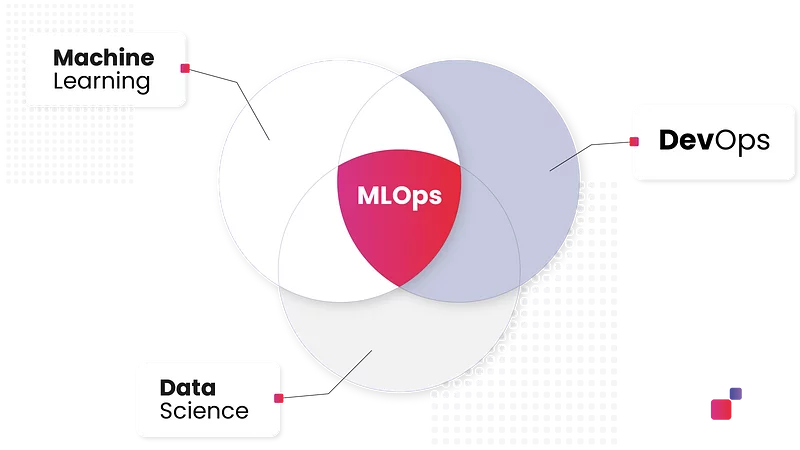
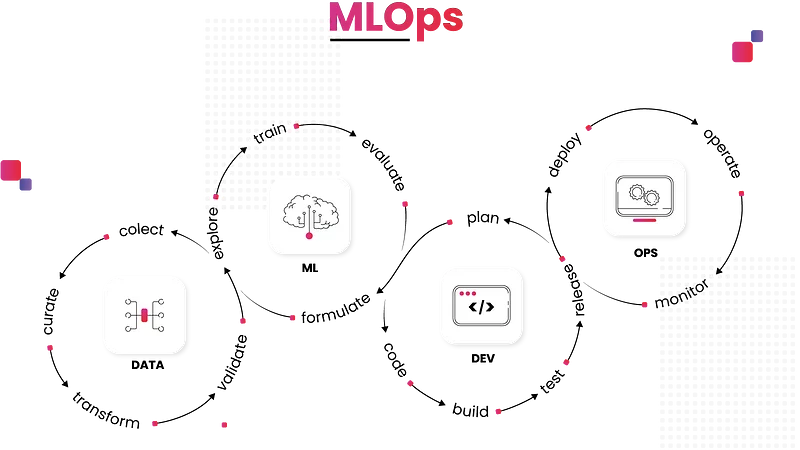
These pipelines have often proven inefficient and error-prone, which has led to the development of new practices to fix these problems. MLOps does this by adding more automation, integration, and collaboration across the whole machine learning lifecycle.
 English
English

 中文
中文
 한국어
한국어
 日本語
日本語